彻底搞懂什么是一次性哈希算法
背景
近期在学习 Go 语言,在 分布式存储 Geecache 练习教程中第一次听到一次性哈希,由于第一次接触后端,不是特别理解,所以记录下以备后续巩固学习。
分配请求
在分布式存储中,往往会通过多台服务器构成集群来提供服务,因为单机的并发量和数据量是有限的,接下来我们称服务器为节点。
假设集群有十个节点,当 节点A 接收到 请求A 时,如果 节点A 没有缓存数据,那么它将会从数据源获取 数据A 并缓存到 节点A 。那么第二次当输入一致时将只有 1/10 的几率选择 节点A 去读取缓存,而有 9/10 的几率会选择其他节点,并再次访问数据源进而存储数据。就会造成在多个节点中,多次缓存同一份数据,导致效率低下,存储空间的浪费。
那么我们该如何将缓存均匀的分布到不同节点进行缓存,并保证但输入一致时,访问同一个节点?
哈希算法
取模运算
通过对输入进行哈希计算,每次计算都是相同的值,这样就可以将某些相同的请求全部打到同一个节点,从而满足分布式系统的负载均衡需求。
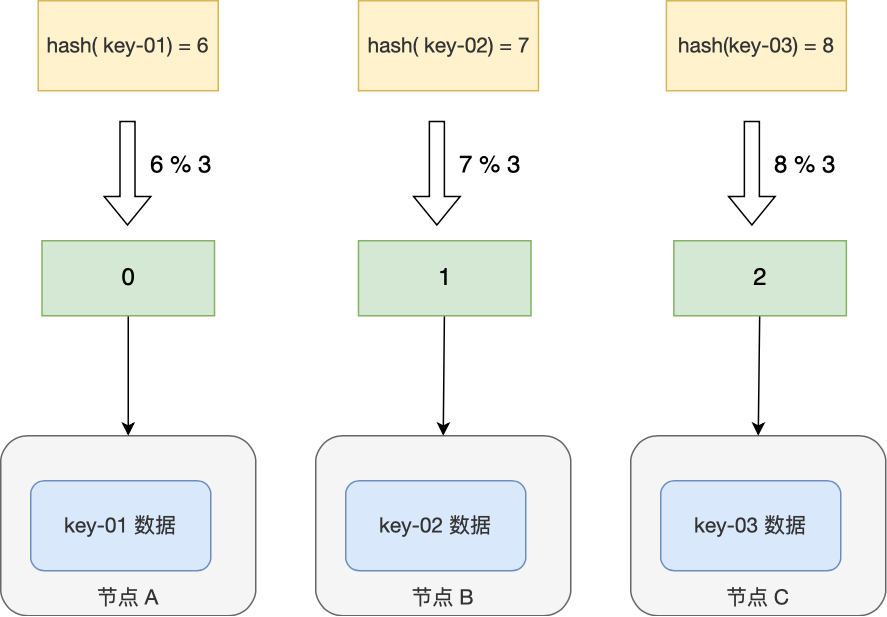
比如当前有三个节点 A、B、C,我们将输入的所有字符的 ASCII 码加起来生成一个 KEY,基于 hash(key) % 3 公式计算得到对应的节点。
缓存雪崩
简单的求取 Hash 值接近了缓存性能的问题,但是当我们增加或删除一个节点时,将会导致取模函数中基数的变化,导致大部分的映射关系发生变化,从而引起缓存值的失效。这时候访问节点时,由于节点上的不存在缓存,将重新去数据源获取数据,容易引起 缓存雪崩。
缓存雪崩:缓存在同一时刻全部失效,造成瞬时
DB请求量大、压力骤增,引起雪崩。常因为缓存服务器宕机,或缓存设置了相同的过期时间引起。
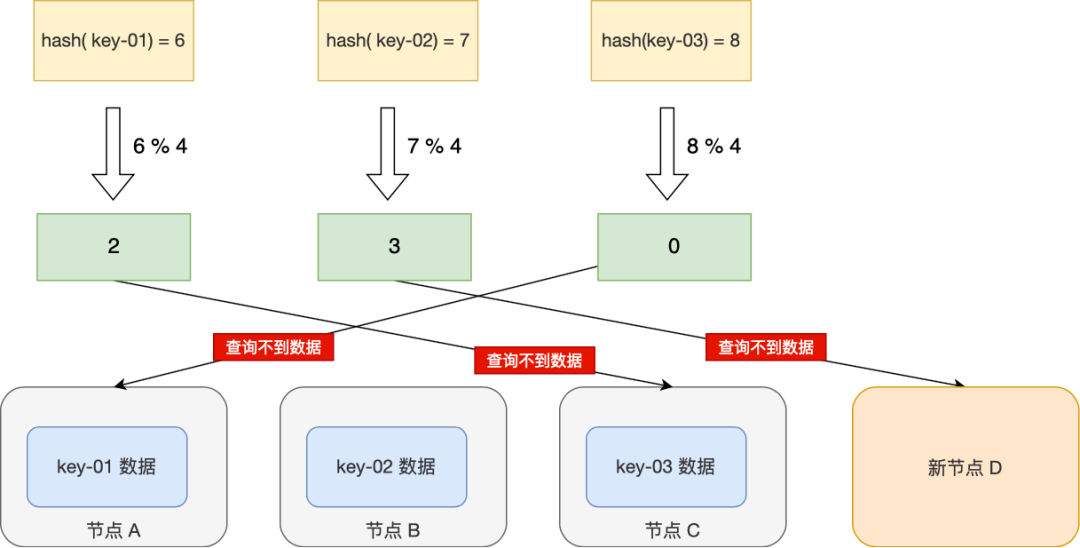
要解决这个问题,我们可以通过数据迁移,假设总数据条数为 M,哈希算法在面对节点数量变化时,最坏情况下所有数据都需要迁移,所以它的数据迁移规模是 O(M),这样数据的迁移成本太高了。
另外一种方式,就是一致性哈希,来避免分布式系统在扩容或者缩容时的数据迁移问题。 5
一致性哈希
原理
一致性哈希算法也采用取模运算,但与哈希算法不同的是,哈希算法是对节点的数量进行取模运算,而一致性哈希算法是对 2³² 进行取模运算,是个固定的值。
我们把 key 映射到 2³² 的空间上,我们可以把它想象成一个从 0 ~ 2³² -1 的环(哈希环)。

一致性哈希通过两步计算:
- 第一步:对存储节点进行哈希计算,也就是对存储节点做哈希映射,比如根据节点的
IP进行哈希。 - 第二步:当对数据进行存储或访问时,对数据进行哈希映射;
所以,一致性哈希是指将「存储节点」和「数据」都映射到一个首尾相连的哈希环上。
问题来了,对「数据」进行哈希映射得到一个结果要怎么找到存储该数据的节点呢?
答案是,映射的结果值往顺时针的方向的找到第一个节点,就是存储该数据的节点。
举个例子,有 3 个节点经过哈希计算,映射到了如下图的位置:
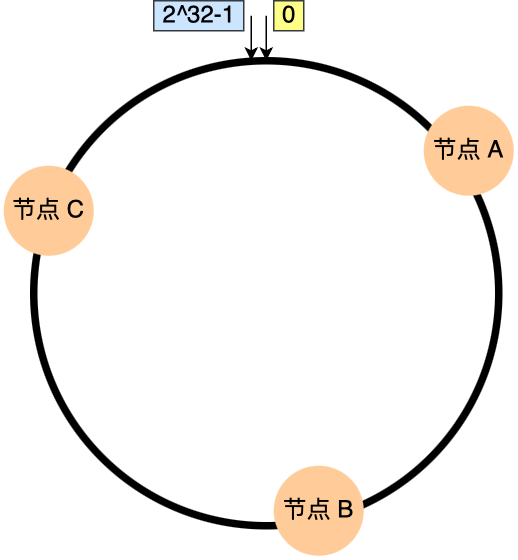
接着,对要查询的 key-01 进行哈希计算,确定此 key-01 映射在哈希环的位置,然后从这个位置往顺时针的方向找到第一个节点,就是存储该 key-01 数据的节点。
比如,下图中的 key-01 映射的位置,往顺时针的方向找到第一个节点就是 节点 A。
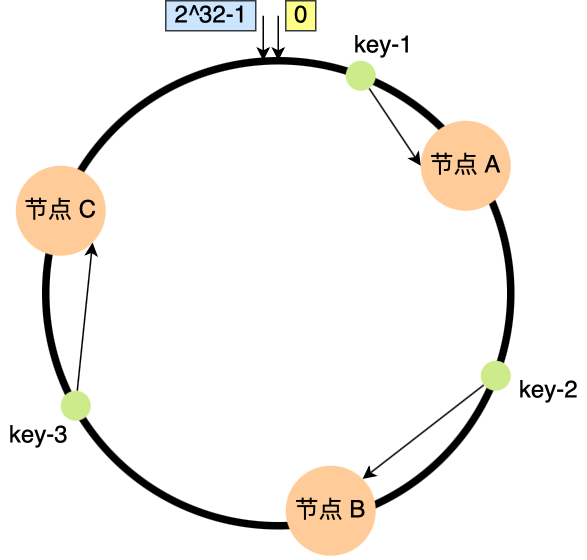
所以,当需要对指定 key 的值进行读写的时候,要通过下面 2 步进行寻址:
- 首先,对
key进行哈希计算,确定此key在环上的位置; - 然后,从这个位置沿着顺时针方向走,遇到的第一节点就是存储
key的节点。
知道了一致哈希寻址的方式,我们来看看,如果增加一个节点或者减少一个节点会发生大量的数据迁移吗?
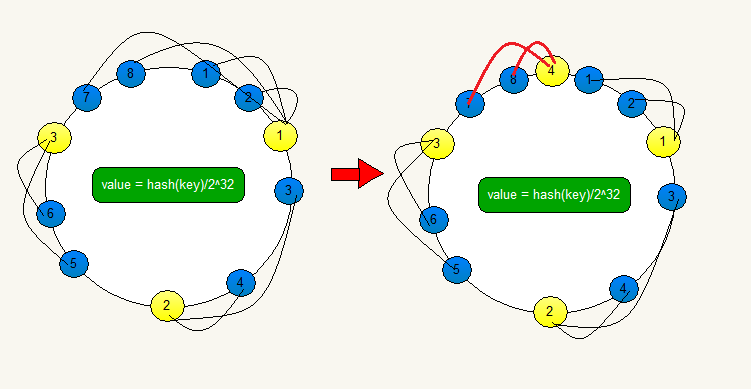
假设节点数量从 3 增加到了 4,新的节点 D 经过哈希计算后映射到了下图中的位置:
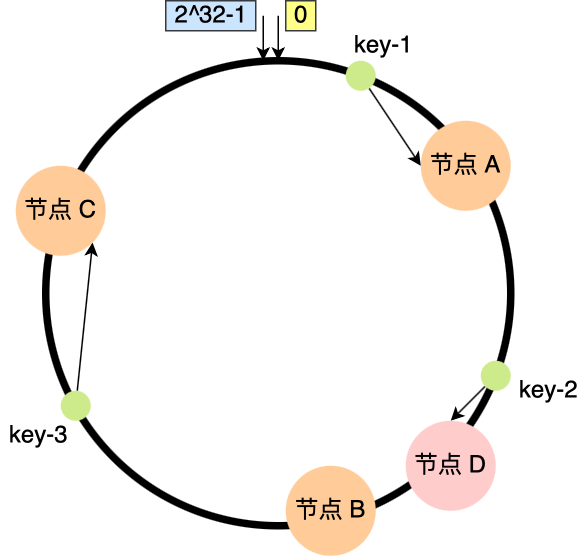
你可以看到,key-01、key-03 都不受影响,只有 key-02 需要被迁移节点 D。
假设节点数量从 3 减少到了 2,比如将 节点 A 移除:
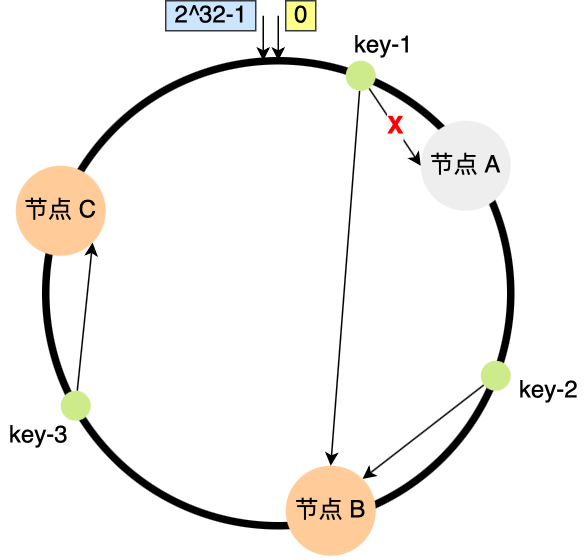
你可以看到,key-02 和 key-03 不会受到影响,只有 key-01 需要被迁移 节点 B。
因此,在一致哈希算法中,如果增加或者移除一个节点,仅影响该节点在哈希环上顺时针相邻的后继节点,其它数据也不会受到影响。
虽然在扩容或者缩容节点的时候,仍然存在缓存失效的问题,但是相比哈希算法,一致性哈希极大程度上减少了数据迁移量,仅影响改节点附近的一小部分数据,而不是全量缓存,从而解决缓存雪崩的问题。
节点分配不均
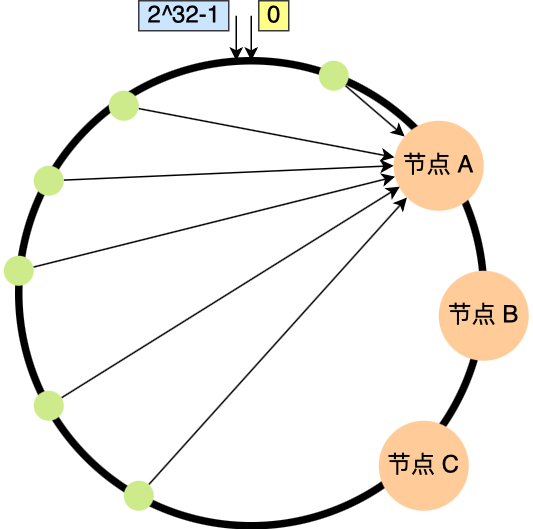
当然,上面这些情况都是建立在比较理想的情况下,3 个节点映射在哈希环还是比较均匀且分散的,所以看起来请求都会「均衡」到每个节点。
但是一致性哈希算法并不保证节点能够在哈希环上分布均匀,由于节点过少,极有可能会带来一个问题,容易引起 key 的倾斜,大量的请求集中在一个节点上,导致缓存节点负载不均。
比如,下图中 3 个节点的映射位置都在哈希环的右半边,极端情况下,所有的请求将全部访问 节点 A:
虚拟节点
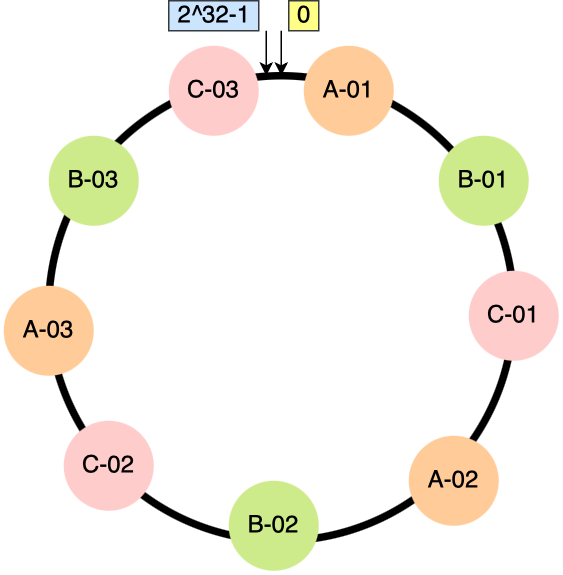
为了解决因节点过少导致的数据倾斜问题,引入了虚拟节点的概念,一个真实节点对应多个虚拟节点。通过将大量的虚拟节点代替真实节点映射在哈希环上,尽可能提高在哈希环上的节点均衡度。
- 第一步,计算虚拟节点的
Hash值,放置在环上。 - 第二步,计算
key的Hash值,在环上顺时针寻找到应选取的虚拟节点,例如是节点 A-1,那么就对应真实节点节点 A。
比如,下图中我们为每个真实节点添加 3 个虚拟节点,原来的 3 个节点就会变成 9 个虚拟节点映射到哈希环上。节点数量是原先的 3 倍,运气好的话,我们将得到相对均匀的哈希环。
虚拟节点除了会提高节点的均衡度以外,还会提高系统的稳定性。当某个节点被移除时,对应的多个虚拟节点均会被移除,而原本访问这些虚拟节点的请求将会通过顺时针方向寻找下一个虚拟节点,并访问到不同的真实节点,从而使多个不同的真实节点共同承担节点变化导致的访问压力。
结论
为了使分布式存储发挥作用,我们引用哈希算法来建立
请求与节点的映射关系,来达到请求分发和缓存的负载均衡。但是当节点数发生改变的时候,哈希算法会以节点数量为基数重新计算映射关系,从而引发缓存雪崩。一致性哈希通过
2³²来取模运算,将节点映射到一个首尾相连的哈希环上。扩缩容节点时仅影响改节点在哈希环上顺时针相邻的后继节点,其他的数据不会受到影响。但是一致性哈希算法不足以将真实的节点均匀地分布在哈希环上,容易出现
节点/数据倾斜,这种极端情况下也会引发雪崩的连锁反应。为了解决这个问题,我们引入了大量的
虚拟节点代替真实节点来映射到哈希环上,提高节点分布的均衡度。所以这里就有两层映射关系:真实节点 <-> 虚拟节点和虚拟节点 <-> 哈希环。通过请求的
Hash值在哈希环上顺时针寻找最近的虚拟节点,再映射到真实节点。引入虚拟节点后,可以提高节点的均衡度,也可以提高系统的稳定性。