celery分布式消息队列简单使用

Celery-分布式任务队列
一、Celery简介
1. 什么是任务队列
任务队列是一种用于在线程或计算机之间分配工作的机制。
任务队列的输入是一个称为任务的工作单元,有专门的职程(Worker)进行不断的监视任务队列,进行执行新的任务工作。
Celery 通过消息机制进行通信,通常使用中间件(Broker)作为客户端和职程(Worker)调节。启动一个任务,客户端向消息队列 发送一条消息,然后中间件(Broker)将消息传递给一个职程(Worker),最后由职程(Worker)执行。
Celery 可以有多个职程(Worker)和中间件(Broker),用来提高Celery的高可用性以及横向扩展能力。
Celery 需要消息中间件来进行发送和接收消息。 RabbitMQ 和 Redis 中间件的功能比较齐全,但也支持其它的实验性的解决方案,其 中包括 SQLite 进行本地开发。
Celery 可以在一台机器上运行,也可以在多台机器上运行,甚至可以跨数据中心运行。
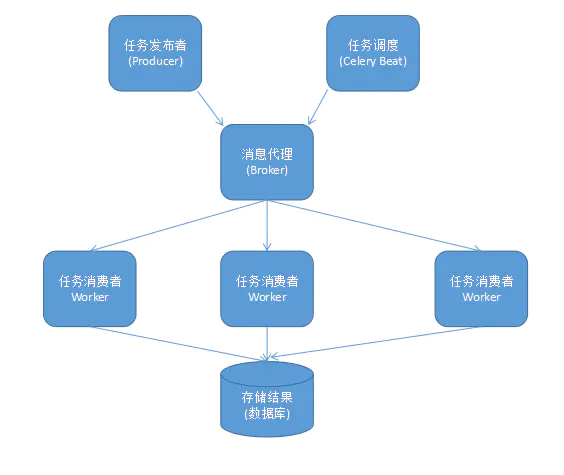
2. Celery组件
Celery 扮演生产者和消费者的角色
Celery Beat:任务调度器。Beat 进程会读取配置文件的内容,周期性的将配置中到期需要执行的任务发送给任务队列。
Celery Worker:执行任务的消费者,通常会在多台服务器运行多个消费者,提高运行效率。
Broker:消息代理,队列本身。 也称为消息中间件。 接受任务生产者发送过来的任务消息,存进队列再按序分发给任务消费方(通常是消息队列或者数据库)。
Producer:任务生产者。 调用 Celery API ,函数或者装饰器,而产生任务并交给任务队列处理的都是任务生产者。
Result Backend : 任务处理完成之后保存状态信息和结果,以供查询。
celery架构图
3. Celery特点
- 高可用
当任务执行失败或执行过程中发生连接中断,celery 会自动尝试重新执行任务。
- 快速
一个单进程的 Celery 每分钟可以处理数以百万的任务,而且延迟仅为亚毫秒(使用 RabbitMQ、 librabbitmq 在优化过后)。
- 灵活
Celery 的每个部分几乎都可以自定义扩展和单独使用,例如自定义连接池、序列化方式、压缩方式、日志记录方式、任务调度、生产者、消费者、中间件(Broker)等。
4. Celery功能
- 监控
可以针对整个流程进行监控,内置的工具可以实时说明当前集群的概况。
- 调度
可以通过调度功能在一段时间内指定任务的执行时间 datetime,也可以根据简单每隔一段时间进行执行重复的任务,支持分钟、小时、星期几,也支持某一天或某一年的Crontab表达式。
- 工作流
可以通过“canvas”进行组成工作流,其中包含分组、链接、分块等等。
简单和复杂的工作流程可以使用一组“canvas“组成,其中包含分组、链接、分块等。
- 资源(内存)泄漏保护
–max-tasks-per-child 参数适用于可能会出现资源泄漏(例如:内存泄漏)的任务。
- 时间和速率的限制
您可以控制每秒/分钟/小时执行任务的次数,或者任务执行的最长时间,也将这些设置为默认值,针对特定的任务或程序进行定制化配置。
- 自定义组件
开发者可以定制化每一个职程(Worker)以及额外的组件。职程(Worker)是用 “bootsteps” 构建的-一个依赖关系图,可以对职程(Worker)的内部进行细粒度控制。
5. 版本要求
Celery 4.0 运行:
Python ❨2.7,3.4,3.5❩
PyPy ❨5.4,5.5❩
这是支持 Python2.7 的最后一个版本,从下一个版本Celery5.x开始,需要Python3.5或更高的版本。
如果您的 Python 运行环境比较老,则需要使用旧版本的Celery:
- Python 2.6:Celery 3.1 或更早版本。
- Python 2.5:Celery 3.0 或更早版本。
- Python 2.4:Celery 2.2 或更早版本。
二、中间件:Brokers
Celery 支持多种消息传输的方式:
RabbitMQ
Redis
Amazon SQS
1. 中间件(Broker)概况
这是不同的中间件比对情况,更多的信息可以在每个中间件的文档中找到。
| 名称 | 状态 | 监控 | 远程控制 |
|---|---|---|---|
| RabbitMQ | 稳定 | 是 | 是 |
| Redis | 稳定 | 是 | 是 |
| Amazon SQS | 稳定 | 否 | 否 |
| Zookeeper | 试验阶段 | 否 | 否 |
目前试验阶段的中间件(Broker)只是功能性的,没有专门的维护人员。
缺少监控就意味着这个监控已经失效,因此相关的 Flower、Celery events、celerymon 和其他基于此功能的监控工具全部失效。
远程管理控制是指可以通过 celery inspect 和 celery control(以及使用远程控制API的工具)在程序运行时检查和管理职程(Worker)的能力。
2. 使用RabbitMQ
安装与配置
RabbitMQ 是默认的中间件(Broker),只需要配置连接的URL即可,不需要安装额外的的配置以及初始化配置信息
1 | broker_url = 'amqp://myuser:mypassword@localhost:5672/myvhost' |
安装 RabbitMQ 服务可以通过 RabbitMQ官网 进行 安装RabbitMQ 。
注意:
如果在安装 RabbitMQ 后,使用 rabbitmqctl 出现 nodedown 错误信息,可以查阅这片文章解决问题:
http://www.somic.org/2009/02/19/on-rabbitmqctl-and-badrpcnodedown/
配置 RabbitMQ
要使用 Celery,需要创一个RabbitMQ账户:
1 | sudo rabbitmqctl add_user myuser mypassword |
修改myuser、mypassword、myvhost为自己配置的配置信息。
关于更多RabbitMQ配置,请查阅 RabbitMQ手册。
3. 使用Redis
配置
Redis 的配置非常的简单,只需要配置 Redis 的 URL :
1 | app.conf.broker_url = 'redis://localhost:6379/0' |
URL 的格式为:
1 | redis://:password@hostname:port/db_number |
结果存储
如果您想保存任务执行返回结果保存到Redis,您需要进行以下配置:
1 | app.conf.result_backend = 'redis://localhost:7379/0' |
三、Celery基本使用
Celery 是一个包含一系列的消息任务队列。您可以不用了解内部的原理直接使用,它的使用时非常简单的。此外 Celery 可以快速与您的产品扩展与集成,以及 Celery 提供了一系列 Celery 可能会用到的工具和技术支持方案。
1. 选择中间件(Broker)
Celery 需要一个中间件来进行接收和发送消息,通常以独立的服务形式出现
RabbitMQ
RabbitMQ 的功能比较齐全、稳定、便于安装。在生产环境来说是首选的。
Redis
Redis 功能比较全,但是如果突然停止运行或断电会造成数据丢失。
2. 安装 Celery
Celery 在 python 的 PyPI 中管理,可以使用 pip 或 easy_install 来进行安装:
1 | pip install celery |
3. 应用
创建第一个 Celery 实例程序,我们把创建 Celery 程序成为 Celery 应用或直接简称为 app,创建的第一个实例程序可能需要包含 Celery 中执行操作的所有入口点,例如创建任务、管理职程(Worker)等,所以必须要导入 Celery 模块。
首先创建 tasks.py:
1 | from celery import Celery |
4. 运行 Celery 职程(Worker)服务
1 | celery -A tasks worker --loglevel=info |
celery worker 的相关参数
1 | Usage: celery worker [options] |
5. 调用异步任务
需要调用我们创建的实例任务,可以通过 delay() 进行调用。
delay() 是 apply_async() 的快捷方法,可以更好的控制任务的执行
1 | from tasks import add |
如果该任务已经有职程(Worker)开始处理,可以通过控制台输出的日志进行查看执行情况。
调用任务会返回一个 AsyncResult 的实例,用于检测任务的状态,等待任务完成获取返回值(如果任务执行失败,会抛出异常)。默认这个功能是不开启的,如果开启则需要配置 Celery 的结果后端,下一小节会详细说明。
6. 保存结果
如果您需要跟踪任务的状态,Celery 需要在某处存储任务的状态信息。Celery 内置了一些后端结果:SQLAlchemy/Django ORM、Memcached、Redis、 RPC (RabbitMQ/AMQP)以及自定义的后端结果存储中间件。
可以使用Redis作为Celery结果后端,使用RabbitMQ作为中间件(Broker)可以使用以下配置(这种组合比较流行):
1 | app = Celery('tasks', backend='redis://localhost', broker='pyamqp://') |
现在已经配置结果后端,重新调用执行任务。会得到调用任务后返回的一个 AsyncResult 实例:
1 | result = add.delay(4, 4) |
ready() 可以检测是否已经处理完毕:
1 | result.ready() |
整个任务执行过程为异步的,如果一直等待任务完成,会将异步调用转换为同步调用:
1 | >>> result.get(timeout=1) |
如果任务出现异常,get() 会再次引发异常,可以通过 propagate 参数进行覆盖:
1 | result.get(propagate=False) |
如果任务出现异常,可以通过以下命令进行回溯:
1 | result.traceback |
7. Celery + Redis 的探究
尝试研究,使用 redis 作为 celery 的 broker 时,celery 的交互操作同 redis 中数据记录的关联关系。
[1] 继续使用上面的tasks.py,直接发起一个任务。
1 | from tasks import add |
执行后可看到 redis 上生成了两个 key
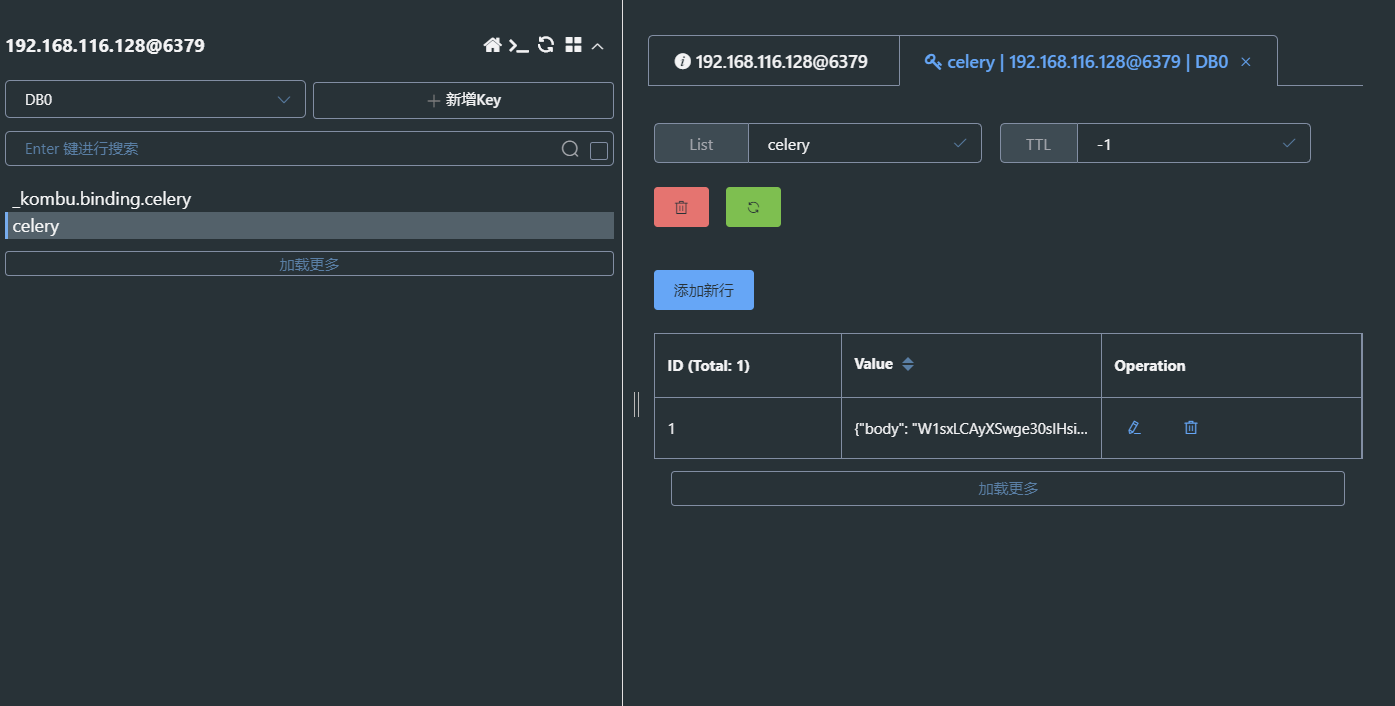
celery:表示当前正在队列中的 task,等待被 worker 所接收_kombu.binding.celery:这个不用管(celery 使用 kombu 维护消息队列,这个是 kombu 生成的对逻辑影响不大)
然后启动 worker
1 | celery -A tasks worker --loglevel=info |
执行后可看到 celery 这个 key 消失了,同时新增了 2 个 key
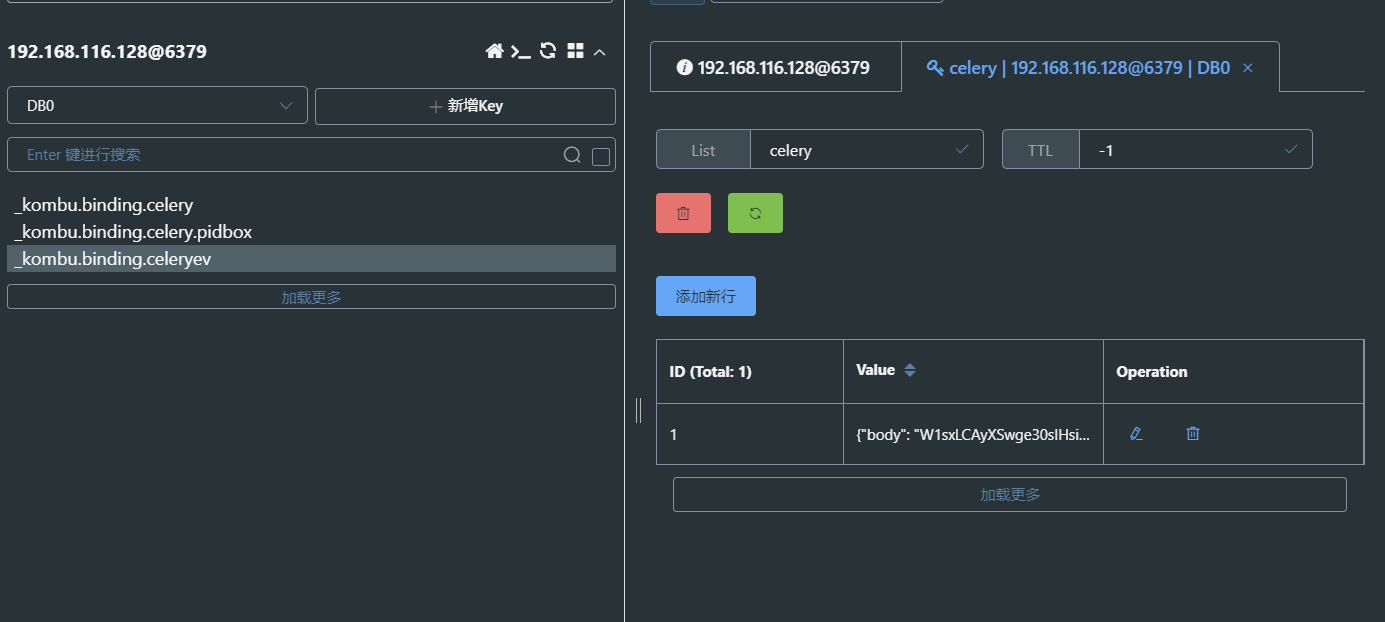
celery 消失说明任务已经被刚启动的 worker 接收了,worker 会自己去执行这个 task,当前没有等待被接收的任务_kombu.binding.celery.pidbox:这个也不用管(也是 kombu 维护的)_kombu.binding.celeryev:这个也不用管(也是 kombu 维护的,用来记下当前连接的 worker)
**[2] ** 下面我们试一下延时任务,使用apply_async()调用任务,并启动worker
1 | add.apply_async((1, 2), countdown=60) |
在 60 秒内查看 redis,可以看到没有出现 celery 这个 key,但多出了另外两个 key
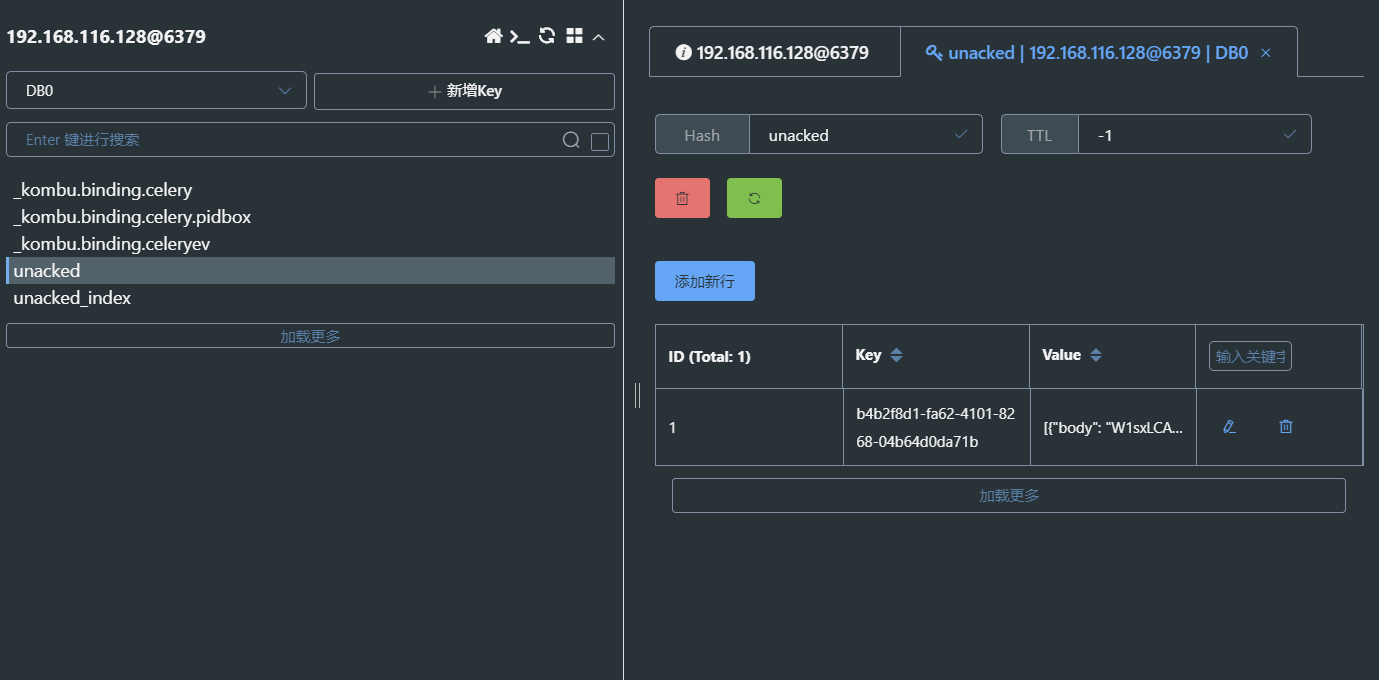
unacked:可以理解为这个是被 worker 接收了但是还没开始执行的 task 列表(因为60秒后才会开始执行)。unacked_index:用户标记上面 unacked 的任务的 id,理论上应该与 unacked 一一对应的。
60 秒后再次查看 redis,可以看到又回到了无任务的状态,这表示被 worker 领取的任务确实在 60 秒后执行了。
[3] 这里在尝试一种异常的情况,worker 领取任务后还没到 60 秒,突然遇到问题退出了。
还是使用apply_async()调用任务,并启动worker,等大约 10 秒后,ctrl+c 中断 worker。
可以看到 redis 中有 celery 这个 key,其中有一条等待领取的任务
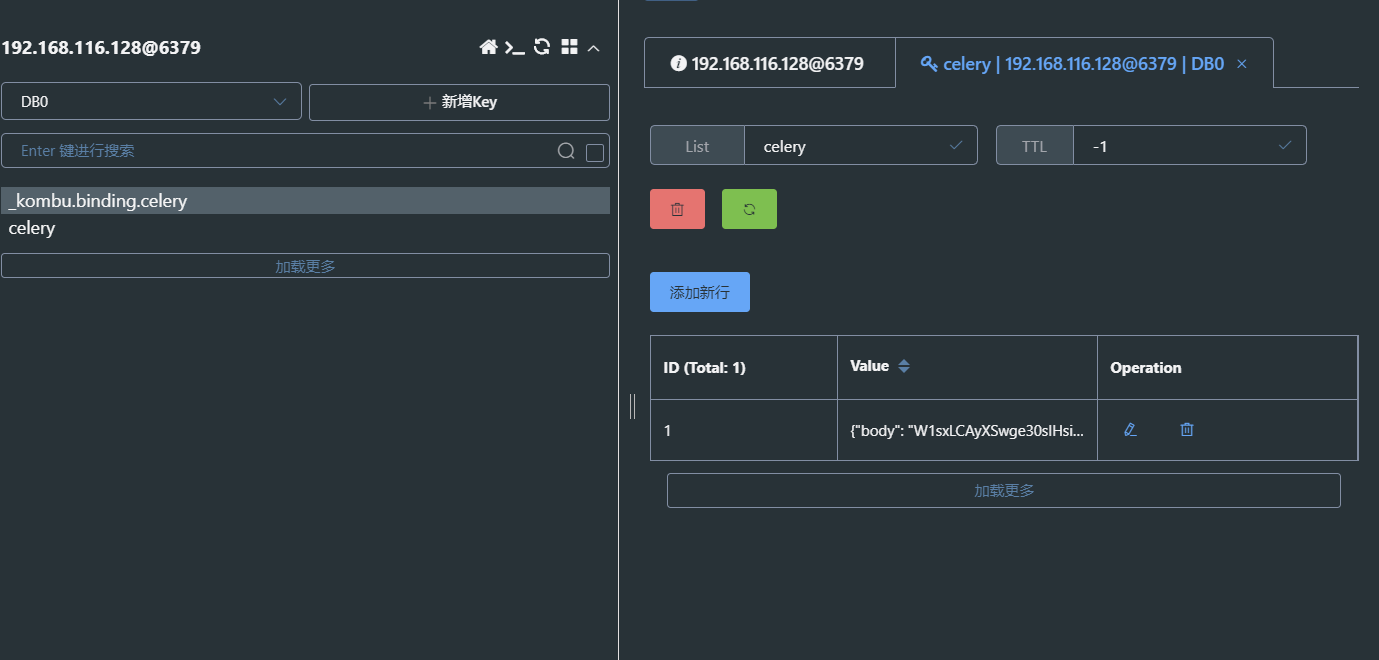
再次启动 worker,可以发现任务被再次正常领取和执行。
由此可以推测出 celery 和 redis 之间交互的基本原理:
- 当发起一个 task 时,会向 redis 的
celerykey 中插入一条记录。 - 如果这时有正在待命的空闲 worker,这个 task 会立即被 worker 领取。
- 如果这时没有空闲的 worker,这个 task 的记录会保留在
celerykey 中。 - task 被 worker 领取后,如果没有到设定的执行时间,这时会将这个 task 的记录从 key
celery中移除,并添加相关信息到unacked和unacked_index中。 - worker 根据 task 设定的期望执行时间执行任务,如果接到的不是延时任务或者已经超过了期望时间,则立刻执行。
- worker 开始执行任务时,通知 redis。(如果设置了 CELERY_ACKS_LATE = True 那么会在任务执行结束时再通知)
- redis 接到通知后,将
unacked和unacked_index中相关记录移除。 - 如果在接到通知前,worker 中断了,这时 redis 中的 unacked 和 unacked_index 记录会重新回到
celerykey 中。(这个回写的操作是由 worker 在 “临死” 前自己完成的,所以在关闭 worker 时为防止任务丢失,请务必使用正确的方法停止它,如:celery multi stop w1 -A proj1) - 在
celerykey 中的 task 可以再次重复上述 2 以下的流程。 - celery 只是利用 redis 的 list 类型,当作个简单的 Queue,并没有使用消息订阅等功能。
友情提醒
1、启动 celery worker 时可以加上 -B 参数使得 schedule 定时任务生效,但要注意如果为同一个项目启动多个 worker 时,只需要其中一个启动命令中加上 -B,否则 schedule 会被多次执行。
2、上面的 1 同时也说明了 schedule task 的执行是由 celery 发起的。也就是说,如果在 django 中使用了 CELERYBEAT_SCHEDULE,那么只要 celery worker -B 启动了,即使 django web 服务没有启动,定时任务也一样会被发起。(推荐使用专门的 celery beat 方法)
3、使用 flower 时,在上述的 “worker 领取任务后突然遇到问题退出了然后又重新启动执行” 这种情况下可能会出现显示不正常的问题。
8. Celery配置
Celery 像家用电器一样,不需要任何配置,开箱即用。它有一个输入和输出,输入端必须连接中间件(Broker),输出端可以连接到结果后端。大多数情况下,使用默认的配置就可以满足,也可以按需配置。查看配置选项可以更加的熟悉 Celery 的配置信息,可以参考 配置和默认配置。
可以直接在程序中进行配置,也可以通过配置模块进行专门配置。例如,通过 task_serializer 选项可以指定序列化的方式:
1 | app.conf.task_serializer = 'json' |
如果需要配置多个选项,可以通过 upate 进行配置:
1 | app.conf.update( |
针对大型的项目,建议使用专用配置模块,进行针对 Celery 配置。不建议使用硬编码,建议将所有的配置项集中化配置。集中化配置可以像系统管理员一样,当系统发生故障时可针对其进行微调。
可以通过 app.config_from_object() 进行加载配置模块:
1 | app.config_from_object('celery_config') |
其中 celery_config 为配置模块的名称,这个是可以自定义修改的。
在上面的实例中,需要在同级目录下创建一个名为 celery_config.py 的文件,添加以下内容:
1 | broker_url = 'pyamqp://' |
可以通过以下命令来进行验证配置模块是否配置正确:
1 | python -m celeryconfig |
Celery 也可以设置任务执行的专用队列,这只是配置模块中一小部分,详细配置如下:
1 | task_routes = { |
Celery 也可以针对任务进行限速,以下为每分钟内允许执行的10个任务的配置:
1 | task_annotations = { |
如果使用的是 RabbitMQ 或 Redis 的话,可以在运行时进行设置任务的速率:
1 | celery -A tasks control rate_limit tasks.add 10/m |
9. 故障处理
职程(Worker)无法正常启动:权限错误
如果使用系统是 Debian、Ubuntu 或其他基于 Debian 的发行版:
Debian 最近把
/dev/shm/重名/run/shm。使用软连接可以解决该问题:
1
ln -s /run/shm /dev/shm
其他:
如果设置了
--pidfile--logfile或--statedb其中的一个参数,必须要保证职程(Worker)对指向的文件/目录可读可写。
任务总处于 PENDING (待处理)状态
所有任务的状态默认都是 PENDING (待处理)状态,Celery 在下发任务时不会更换任务状态
确认任务没有启用
ignore_result如果启用,会强制跳过任务更新状态。
确保
task_ignore_result未启用。确保没有旧的职程(Worker)正在运行。
启动多个职程(Worker)比较容易,在每次运行新的职程(Worker)之前需要确保之前的职程是否关闭。
未配置结果后端的职程(Worker)是否正在运行,可能会消费当前的任务消息。
–pidfile参数设置为绝对路径,确保该情况不会出现。确认客户是否配置正确。
可能由于某种场景,客户端与职程(Worker)的后端不配置不同,导致无法获取结果,所以需要确保配置是否正确:
1
2result = task.delay(…)
print(result.backend)
四、Celery 进阶使用
1. 任务调用
- 执行方式
标准的执行选项以及三种方法:
apply_async(args[, kwargs[, …]])。发送任务消息delay(*args, **kwargs)。发送任务消息的快捷方式,但不支持执行选项。calling (__call__)。任务将不会由 Worker 执行,而是在当前进程中执行。
示例:
1 | T.delay(arg, kwarg=value) |
- 任务回调
Celery支持将任务链接在一起,以便一个任务紧随另一个任务。回调任务将与父任务的结果一起用作部分参数:
1 | add.apply_async((2, 2), link=add.s(16)) |
在这里,第一个任务的结果(4)将被发送到一个新任务,该新任务将之前的结果加16,形成表达式 (2+2)+16
如果task引发异常(errback),还可以使用错误回调,与常规回调的行为不同的是,它将传递父任务的ID,而不是结果。这是因为不一定总是可以序列化引发的异常,因此错误回调需要启用结果后端,并且任务必须检索任务的结果。
错误回调函数示例:
1 |
|
可以使用link_error执行选项将其添加到任务中:
1 | add.apply_async((2, 2), link_error=error_handler.s()) |
此外,link和link_error选项都可以表示为列表:
1 | add.apply_async((2, 2), link=[add.s(16), other_task.s()]) |
然后将依次调用回调/错误返回,并且将使用父任务的返回值作为部分参数来调用所有回调。
- on_message 捕获任务状态
Celery可以通过设置on_message回调支持捕获所有状态更改。
例如,对于长时间运行的任务以发送任务进度,您可以执行以下操作:
1 |
|
1 | r = hello.apply_async(args=(1, 2)) |
将生成如下输出:
1 | {'status': 'PROGRESS', 'result': {'progress': 50}, 'traceback': None, 'children': [], 'date_done': None, 'task_id': '55fc6e9e-eba8-4229-9058-b06d10172752'} |
- 定时执行
通过 ETA(estimated time of arrival),可以设置特定的日期和时间执行任务。countdown是一种以秒为单位设置ETA的快捷方式。
1 | result = add.apply_async((2, 2), countdown=3) |
- 任务过期时间
expires参数定义了一个可选的过期时间,既可以使用任务发布之后的多少秒,也可以使用一个特定的datetime
1 | add.apply_async((10, 10), expires=60) # 60秒之后过期 |
当 Worker 收到过期的任务时,会将任务标记为 REVOKED(TaskRevokedError)
- 任务重试
当连接失败时,Celery会自动重试发送消息,并且可以配置重试行为(例如重试频率或最大重试次数)或一起禁用。
要禁用重试,可以将retry执行选项设置为False:
1 | add.apply_async((2, 2), retry=False) |
重试策略(retry_policy)包含以下键:
max_retries:放弃之前的最大重试次数,值None意味着它将永远重试,默认为重试3次。
interval_start: 定义两次重试之间要等待的秒数,默认值为0(第一次重试将立即执行)。
interval_step:每次连续重试时,此数字将被添加到重试延迟中(浮点数或整数),默认值为0.2。
interval_max:重试之间等待的最大秒数(浮点数或整数),默认值为0.2。
1 | add.apply_async((2, 2), retry=True, retry_policy={ |
重试的最长时间为0.4秒。默认情况下将其设置为较短,因为如果代理连接断开,则连接失败可能导致重试堆效应–例如,许多Web服务器进程正在等待重试,从而阻止了其他传入请求。
2. Canvas:设计工作流程
- 签名
signature() 可以包装单个任务调用的参数,关键字参数和执行选项,以便可以将其传递给函数,甚至进行序列化并通过网络发送。
1 | from celery import signature |
或者您可以使用任务的signature方法创建一个:
1 | add.signature((2, 2), countdown=10) |
它支持调用API delay, apply_async等等,包括被直接调用(__call__)
1 | add(2, 2) |
- group
组,也是一种签名,其中包含应并行应用的任务列表。
您可以轻松创建一组任务以并行执行:
1 | from celery import group |
- chain
链,使我们可以将签名链接在一起,以便一个被另一个调用,本质上形成了回调链。调用链将调用当前进程中的任务,并返回链中最后一个任务的结果:
简单链:
1 | from celery import chain |
也可以使用管道来编写:
1 | (add.s(2, 2) | add.s(4) | add.s(8))().get() |
不变的签名
签名可以是部分签名,因此可以将参数添加到现有签名中,但是您可能并不总是希望这样,例如,如果您不希望链中上一个任务的结果传递到下一个任务中,在这种情况下,您可以将签名标记为不可变的,这样就不能更改参数:
1 | add.signature((2, 2), immutable=True) |
还有一个.si()捷径,这是创建签名的首选方式:
1 | add.si(2, 2) |
这样就可以创建一系列独立的任务:
1 | res = (add.si(2, 2) | add.si(4, 4) | add.si(8, 8))() |
- chord
chord就像是带有回调的组,由标题组和主体组成,其中主体是应在标题中的所有任务完成后执行的任务:
1 | from celery import chord |
上面的示例创建了10个任务,这些任务全部并行启动,当所有任务完成时,返回值组合到一个列表中并发送给该xsum任务。
将组与另一个任务链接在一起将自动将其升级为chord:
1 | c3 = (group(add.s(i, i) for i in range(10)) | xsum.s()) |
- map 与 starmap
map并且starmap是内置任务,它们为序列中的每个元素调用提供调用的任务。
它们与group的不同之处在于:
- 仅发送一条任务消息。
- 该操作是顺序的。
例如使用map:
1 | from proj.tasks import add |
与执行以下任务相同:
1 |
|
使用starmap:
1 | ~add.starmap(zip(range(10), range(10))) |
与执行以下任务相同:
1 |
|
- chunks
chunks 可让您将可重复的工作分成多个部分,如果有100万个对象,则可以创建10个任务,每个任务有10万个对象。
有些人可能会担心将任务分块会导致并行度降低,但是对于繁忙的集群而言,情况很少如此,实际上,因为避免了消息传递的开销,这可能会大大提高性能。
要创建块签名,可以使用 app.Task.chunks()
1 | add.chunks(zip(range(100), range(100)), 10) |
与group发送消息的行为一样,将在当前进程中调用时进行:
1 | from proj.tasks import add |
调用时.apply_async将创建一个专用任务,以便将单个任务应用在工作程序中:
1 | add.chunks(zip(range(100), range(100)), 10).apply_async() |
您还可以将块转换为组:
1 | group = add.chunks(zip(range(100), range(100)), 10).group() |
3. 定期任务
**celery beat **是一个调度程序,它定期启动任务,然后由群集中的可用工作程序节点执行任务。默认情况下,条目是从beat_schedule设置中获取的,但是也可以使用自定义存储,例如将条目存储在SQL数据库中。必须确保一次只有一个调度程序运行,否则最终将导致重复的任务。
要定期调用任务,您必须在beat schedule列表中添加一个条目。
示例:每30秒运行task.add任务。
1 | app.conf.beat_schedule = { |
crontab 调度器
如果要对执行任务的时间(例如,一天中的特定时间或一周中的某天)进行更多控制,则可以使用crontab计划类型:
1 | from celery.schedules import crontab |
Crontab表达式的语法非常灵活,一些例子:
| 例 | 含义 |
|---|---|
crontab() |
每分钟执行一次。 |
crontab(minute=0, hour=0) |
每天午夜执行。 |
crontab(minute=0, hour='*/3') |
每三个小时执行一次:午夜,凌晨3点,6am,9am,中午,3pm,6pm,9pm。 |
crontab(minute=0, hour='0,3,6,9,12,15,18,21') |
同上。 |
crontab(minute='*/15') |
每15分钟执行一次。 |
crontab(day_of_week='sunday') |
在星期日的每一分钟执行。 |
crontab(minute='*', hour='*', day_of_week='sun') |
同上。 |
crontab(minute='*/10', hour='3,17,22', day_of_week='thu,fri') |
每十分钟执行一次,但仅在周四或周五的凌晨3-4点,下午5-6点以及晚上10-11点之间执行。 |
crontab(minute=0, hour='*/2,*/3') |
每隔一小时执行一次,每一小时被三整除。这意味着:每小时除外:1 am、5am、7am、11am、1pm、5pm、7pm、11pm |
crontab(minute=0, hour='*/5') |
执行小时可被5整除。这意味着它在下午3点而不是下午5点被触发(因为3pm等于24小时时钟值“ 15”,可被5整除)。 |
crontab(minute=0, hour='*/3,8-17') |
每小时执行一次可被3整除的时间,在办公时间内(上午8点至下午5点)每小时执行一次。 |
crontab(0, 0, day_of_month='2') |
在每个月的第二天执行。 |
crontab(0, 0, day_of_month='2-30/2') |
在每个偶数天执行一次。 |
crontab(0, 0, day_of_month='1-7,15-21') |
在每月的第一和第三周执行。 |
crontab(0, 0, day_of_month='11', month_of_year='5') |
每年5月11日执行。 |
crontab(0, 0, month_of_year='*/3') |
在每个季度的第一个月每天执行一次。 |
solar 调度器
如果您有应根据日出,日落,黎明或黄昏执行的任务,则可以使用 solar计划类型:
1 | from celery.schedules import solar |
参数很简单: solar(event, latitude, longitude)
纬度和经度使用正确的符号:
| Sign | Argument | 含义 |
|---|---|---|
+ |
latitude |
北 |
- |
latitude |
南 |
+ |
longitude |
东 |
- |
longitude |
西方 |
可能的事件类型:
| 事件 | 含义 |
|---|---|
dawn_astronomical |
在天空不再完全黑暗的那一刻执行。这是当太阳低于地平线18度时。 |
dawn_nautical |
当有足够的阳光照亮地平线并区分一些物体时执行。正式地,当太阳低于地平线12度时。 |
dawn_civil |
当有足够的光线可辨别物体时执行,以便可以开始户外活动;正式地,当太阳在地平线以下6度时。 |
sunrise |
当早晨早晨太阳的上边缘出现在东部地平线上方时执行。 |
solar_noon |
当当天太阳最高到地平线以上时执行。 |
sunset |
当傍晚太阳的后缘在西方地平线上消失时执行。 |
dusk_civil |
当物体仍然可以区分并且可见一些恒星和行星时,在民航末尾执行。正式地,当太阳低于地平线6度时。 |
dusk_nautical |
当太阳低于地平线12度时执行。物体不再可分辨,并且肉眼不再看到地平线。 |
dusk_astronomical |
在天空完全变暗的那一刻执行;正式地,当太阳低于地平线18度时。 |
要启动celery定期调度任务:
1 | celery -A proj beat |
您还可以通过启用workers -B 选项将beat嵌入到worker中,如果您永远不会运行一个以上的worker节点,这很方便,但是它不常用,因此不建议用于生产环境:
1 | celery -A proj worker -B |
Beat需要将任务的最后运行时间存储在本地数据库文件(默认情况下命名为celerybeat-schedule)中,因此需要访问才能在当前目录中进行写操作,或者可以为此文件指定一个自定义位置:
1 | celery -A proj beat -s /home/celery/var/run/celerybeat-schedule |
4. 路由任务
自动路由
配置 task_routes 参数,celery将自动创建尚未在其中定义的命名队列 。这样可以轻松执行简单的路由任务。
1 | task_routes = {'feed.tasks.import_feed': {'queue': 'feeds'}} |
启用上述配置后,import_feed 任务将被路由到 feeds 队列,其他任务将被路由到默认队列(默认是 celery )。
此外,还可以使用全局模式匹配甚至正则表达式来匹配名称空间中的所有任务:
1 | app.conf.task_routes = {'feed.tasks.*': {'queue': 'feeds'}} |
启用路由配置后,就可以在启动 Worker 时使用 -Q 选项指定该 Worker 要处理的队列:
1 | celery -A proj worker -Q feeds |
可以指定任意数量的队列,因此也可以使该服务器处理默认队列:
1 | celery -A proj worker -Q feeds,celery # 逗号后面加空格会报错 |
手动路由配置
假设您有两个服务器x和y分别处理常规任务,一个服务器z仅仅处理与feed相关的任务,则可以使用以下配置:
1 | from kombu import Queue |
要将任务路由到feed_tasks队列,可以在task_routes设置中添加一个条目 :
1 | task_routes = { |
您还可以在调用任务时使用 routing_key 参数覆盖此参数 :
1 | from tasks import import_feed |
任务优先级
- RabbitMQ
可以通过设置x-max-priority参数将队列配置为支持优先级 :
1 | from kombu import Exchange, Queue |
可以使用以下 task_queue_max_priority 设置来设置所有队列的默认值 :
1 | app.conf.task_queue_max_priority = 10 |
还可以使用以下task_default_priority设置来指定所有任务的默认优先级 :
1 | app.conf.task_default_priority = 5 |
- Redis
尽管芹菜Redis运输确实尊重优先领域,但Redis本身没有优先概念。在尝试使用Redis实施优先级之前,请阅读此说明,因为您可能会遇到一些意外的行为。
要根据优先级开始计划任务,您需要配置queue_order_strategy传输选项。
1 | app.conf.broker_transport_options = { |
通过为每个队列创建n个列表来实现优先级支持。这意味着即使有10(0-9)个优先级,默认情况下也会将其合并为4个级别以节省资源。这意味着名为celery的队列实际上将分为4个队列:
1 | ['celery0', 'celery3', 'celery6', 'celery9'] |
如果需要更多优先级,可以设置priority_steps传输选项:
1 | app.conf.broker_transport_options = { |
也就是说,请注意,这永远不会像在服务器级别实现的优先级那样好,并且充其量可能是最好的。但这对于您的应用程序可能仍然足够好。
5. 监控和管理
Worker 管理命令
status:列出此集群中的活动节点。
1 | celery -A proj status |
result:显示任务的结果。
1 | celery -A proj result -t tasks.add 4e196aa4-0141-4601-8138-7aa33db0f577 |
purge:从所有已配置的任务队列中清除消息。-Q选项指定要清除的队列,-X选项排除清除队列:
1 | celery -A proj purge # 全部清除 |
inspect active:列出活动任务(当前正在执行的所有任务)。
1 | celery -A proj inspect active |
inspect scheduled:列出计划的ETA任务(设置了eta或countdown参数的任务 )。
1 | celery -A proj inspect scheduled |
inspect reserved:列出保留任务(这将列出工作者已经预取的所有任务,并且当前正在等待执行)。
1 | celery -A proj inspect reserved |
inspect revoked:列出已撤销任务的历史记录
1 | celery -A proj inspect revoked |
inspect registered:列出所有已注册任务
1 | celery -A proj inspect registered |
inspect stats:显示worker统计信息
1 | celery -A proj inspect stats |
inspect query_task:按ID显示有关任务的信息```shell
$ celery -A proj inspect query_task e9f6c8f0-fec9-4ae8-a8c6-cf8c8451d4f81
2
3
4
5
- `control enable_events` :启用事件
```shell
$ celery -A proj control enable_eventscontrol disable_events:禁用事件migrate:将任务从一个代理迁移到另一个代理
1 | celery -A proj migrate redis://localhost amqp://localhost |
Flower :celery实时监控工具
功能:
- 使用Celery Events进行实时监控
- 任务进度和历史
- 能够显示任务详细信息(参数,开始时间,运行时等)
- 图形和统计
- 遥控
- 查看工作人员状态和统计数据
- 关闭并重新启动工作程序实例
- 控制工作池大小和自动缩放设置
- 查看和修改工作人员实例从中使用的队列
- 查看当前正在运行的任务
- 查看计划的任务(ETA /倒计时)
- 查看保留和撤销的任务
- 应用时间和速率限制
- 配置查看器
- 撤销或终止任务
- HTTP API
- 列出工人
- 关掉一个工人
- 重新启动工人池
- 增加工人的游泳池
- 缩工池
- 自动缩放工人池
- 从队列开始消耗
- 停止从队列消费
- 列出任务
- 列出(看到)任务类型
- 获取任务信息
- 执行任务
- 按名称执行任务
- 获取任务结果
- 更改任务的软限制和硬限制
- 任务的更改速率限制
- 撤销任务
- OpenID验证
用法:
您可以使用pip安装Flower:
1 | pip install flower |
运行flower命令将启动您可以访问的Web服务器:
1 | celery -A proj flower |
默认端口为5555,但是您可以使用 --port 参数更改此端口:
1 | celery -A proj flower --port=5555 |
Broker URL也可以通过 --broker 参数传递 :
1 | celery flower --broker=amqp://guest:guest@localhost:5672// |
6. 最佳实践
- 尽量不要使用数据库作为 AMQP Broker
随着 worker 的不断增多可能给数据库 IO 和连接造成很大压力。更具体来说不要把 Celery 的 task 数据和应用数据放到同一个数据库中。
- 使用多个队列
对于不同的 task ,尽量使用不同的队列来处理。在 celery_config.py 中定义
1 | task_queues=( |
在 task 上定义
1 |
|
- 定义具有优先级的 workers
假如有一个 taskA 去处理一个队列 A 中的信息,一个 taskB 去处理队列 B 中的数据,然后起了 x 个 worker 去处理队列 A ,其他的 worker 去处理队列 B。而这时也可能会出现队列 B 中一些 task 急需处理,而此时堆积在队列 B 中的 tasks 很多,需要耗费很长时间来处理队列 B 中的 task。此时就需要定义优先队列来处理紧急的 task。
celery 中可以在定义 Queue 时,指定 routing_key
1 | task_queues=( |
然后定义
1 | task_routes={ |
在启动 worker 时指定 routing_key
1 | celery worker -E -l INFO -n workerA -Q other_high |
- 使用 celery 的错误处理机制
一般情况下可能因为网络问题,或者第三方服务暂时性错误而导致 task 执行出错。这时可以使用 celery task 的重试机制。
1 |
|
一般添加 default_retry_delay 重试等待时间和 max_retries 重试次数来限定,防止任务无限重试。
- 使用 Flower
Flower 为监控 celery tasks 和 workers 提供了一系列的便利。他使用 Web 界面提供 worker 当前状态, task 执行进度,各个 worker 详细信息,甚至可以在网页上动态更行执行速率。
- 只有在真正需要时才去追踪 celery 的 result
任务的状态存储任务在退出时成功或者失败的信息,这些信息有些时候很重要,尤其是在后期分析数据时,但是大部分情况下更加关心 task 执行过程中真正想要保存的数据,而不是任务的状态。
所以,可以使用 task_ignore_result = True 来忽略任务结果。
- 不要将 Database/ORM 对象传入 tasks
不应该讲 Database objects 比如一个 User Model 传入在后台执行的任务,因为这些 object 可能包含过期的数据。相反应该传入一个 user id ,让 task 在执行过程中向数据库请求全新的 User Object。
- 尽量简化 tasks
task 应该简洁 (concise):
- 将主要 task 逻辑包含在对象方法或者方法中
- 确保方法抛出明确的异常 (identified exceptions)
- 只有在切当的时机再实现重试机制
假设需要实现一个发送邮件的 task:
1 | import requests |
通常任务真实的实现只有一层,而剩余的其他部分都是错误处理。而通常这么处理会更加容易维护。
- 设置 task 超时
设置一个全局的任务超时时间
1 | task_soft_time_limit = 600 # 600 seconds |
超时之后会抛出 SoftTimeLimitExceeded 异常
1 | from celery.exceptions import SoftTimeLimitExceeded |
同样,定义任务时也能够指定超时时间,如果任务 block 尽快让其失败,尽量配置 task 的超时时间。不让长时间 block task 的进程。
1 |
|
- 将 task 重复部分抽象出来
使用 task 的基类来复用部分 task 逻辑
1 | from myproject.tasks import app |
- 将大型 task 作为类
一般情况下将使用方法作为 task 就已经足够,如果遇到大型 task ,可以将其写成类:
1 | class handle_event(BaseTask): # BaseTask inherits from app.Task |
- 单元测试
直接调用 worker task 中的方法,不要使用 task.delay() 。 或者使用 Eager Mode,使用 task_always_eager 设置来启用,当启用该选项之后,task 会立即被调用。而 这两种方式都只能测试 task worker 中的内容,官方并不建议这么做。
- 对于执行时间长短不一的任务建议开启 -Ofair
celery 中默认都会有 prefork pool 会异步将尽量多的任务发送给 worker 执行,这也意味着 worker 会预加载一些任务。这对于通常的任务会有性能提升,但这也容易导致因为某一个长任务处理时间长,而导致其他任务处于长时间等待状态。
对于执行时间长短不一的任务可以开启 -Ofair
1 | celery -A proj worker -l info -Ofair |
- 设置 worker 的数量
Celery 默认会开启和 CPU core 一样数量的 worker,如果想要不想开启多个 worker ,可以通过启动时指定 --concurrency 选项
1 | --concurrency=1 |
- 在 Celery 中使用多线程
上面提到使用 --concurrency=1 或者 -c 1 来设置 worker 的数量,Celery 同样支持 Eventlet 协程方式,如果你的 worker 有大量的 IO 操作,网络请求,那么此时使用 Eventlet 协程来提高 worker 的执行效率。确保在使用 Eventlet 之前对 Eventlet 非常了解,否则不要轻易使用
1 | celery -A proj worker -P eventlet -c 10 |
7. 并发
启用Eventlet
可以使用 worker -P 选项启用Eventlet。
1 | celery -A proj worker -P eventlet -c 1000 |